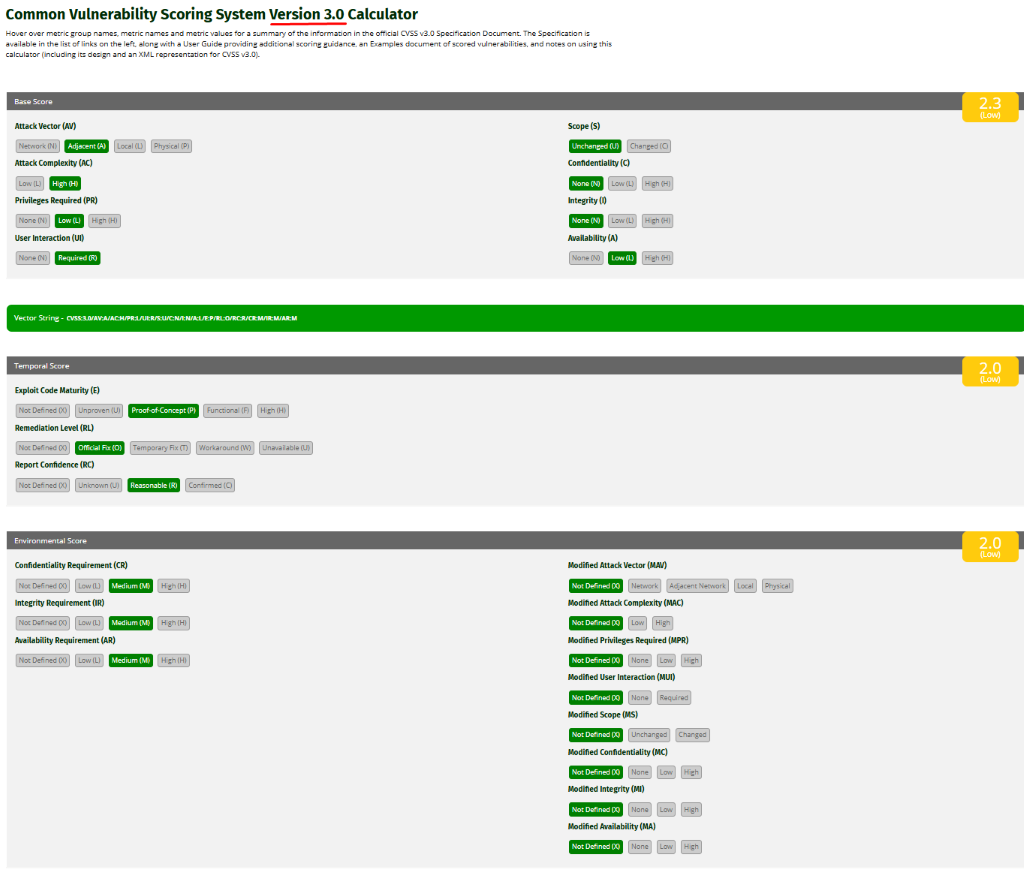
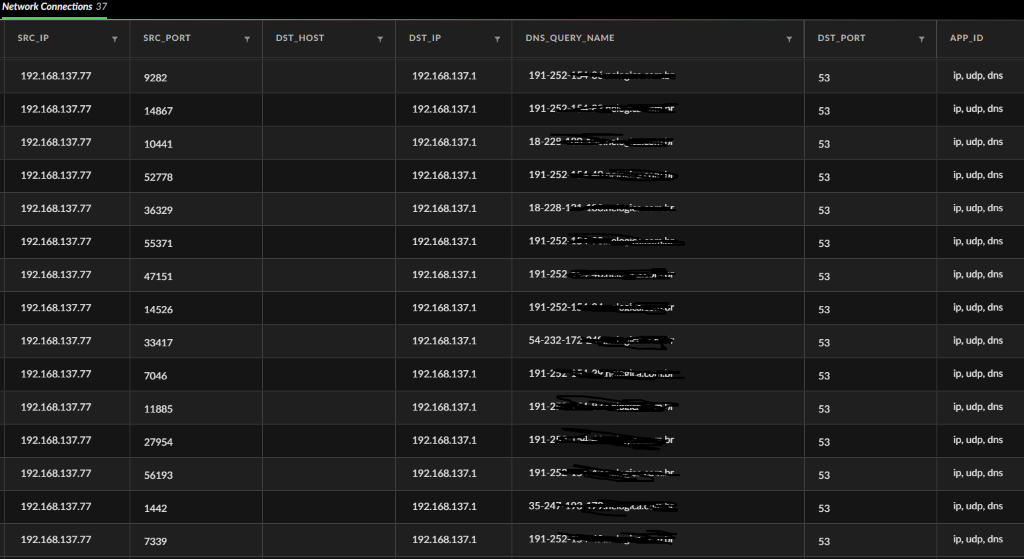
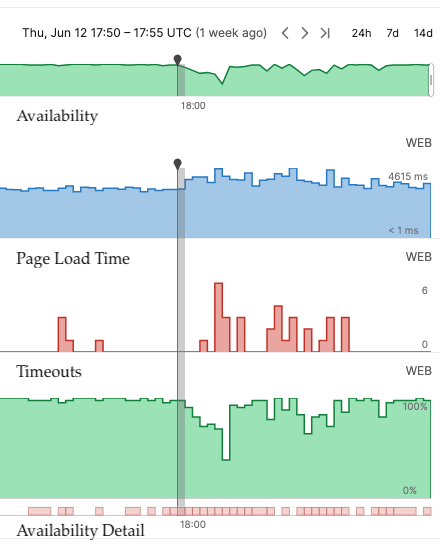
Embora ter ferramentas de proteção são importantes, entender a mentalidade do atacante, como conhecer quais as táticas e métodos utilizados por ele durante um ataque, também é fundamental para os profissionais de cibersegurança.
Por que utilizar o MITRE ATT&CK? O que é?
Criado pela MITRE, o ATT&CK é um framework, uma base de conhecimento global gratuita, contendo informações como as táticas, técnicas e procedimentos adotados por cibercriminosos, baseado em estudos de caso real de incidentes, foram identificadas e mapeadas as informações de como os adversários agem e o ciclo de vida de um ataque no ambiente de tecnologia.
O framework da Mitre ATT&CK foi organizado em um modelo de matriz de domínios tecnológicos, onde buscaram organizar as informações para os comportamentos do adversário, seguindo uma divisão em matrizes de domínios tecnológicos, conforme abaixo:
- Enterprise ATT&CK: Representando informações para ataques a redes empresariais e tecnologias de nuvem para ambientes corporativos.
- Mobile ATT&CK: Representando informações para ataques direcionados a dispositivos móveis.
- ICS ATT&CK: Representando informações para ataques de sistemas de controle industrial (ICS).
Baseado em sua matriz de domínio tecnológico, foi estruturado as informações dividindo em “táticas, técnicas e subtécnicas” para os comportamentos do adversário, seguindo as definições abaixo:
- Táticas: Representam o “porque”, seria o objetivo do atacante.
- Técnicas: Representam o “como”, como alcançar o objetivo definido pelas táticas.
- Subtécnicas: Seria um nível maior de detalhamento das técnicas e comportamentos do adversário.
Frameworks como o do Mitre ATT&CK, permitem que as equipes de segurança antecipem movimentos de atacantes e realizem uma proteção de forma proativa nas organizações, antecipando ações maliciosas e ajudando a implementar controles mais eficazes nos ambientes de tecnologia.
Texto acima foi um breve resumo do que é ATT&CK e podemos encontrar mais informações acessando os endereços: Get Started | MITRE ATT&CK® / MITRE ATT&CK® .
Graduado em Engenharia da Computação e com pós-graduação em Gestão de Tecnologia pela Fatec-RP e Bigdata pelo Senac-RP.