O período de festas está se aproximando e, com ele, o tão esperado “recesso de fim de ano”, época muito aguardada por trabalhadores que buscam aproveitar esse momento para passar tempo com a família e descansar. Como sempre, nem tudo são flores. Sendo assim, nesta minha abordagem, gostaria de levantar alguns alertas que devem ser considerados e que, caso sejam desprezados, podem resultar no recebimento de uma ligação desesperada do seu gestor às 3:00 da manhã, na madrugada do dia de Natal.
Menor Contingente, maiores riscos!
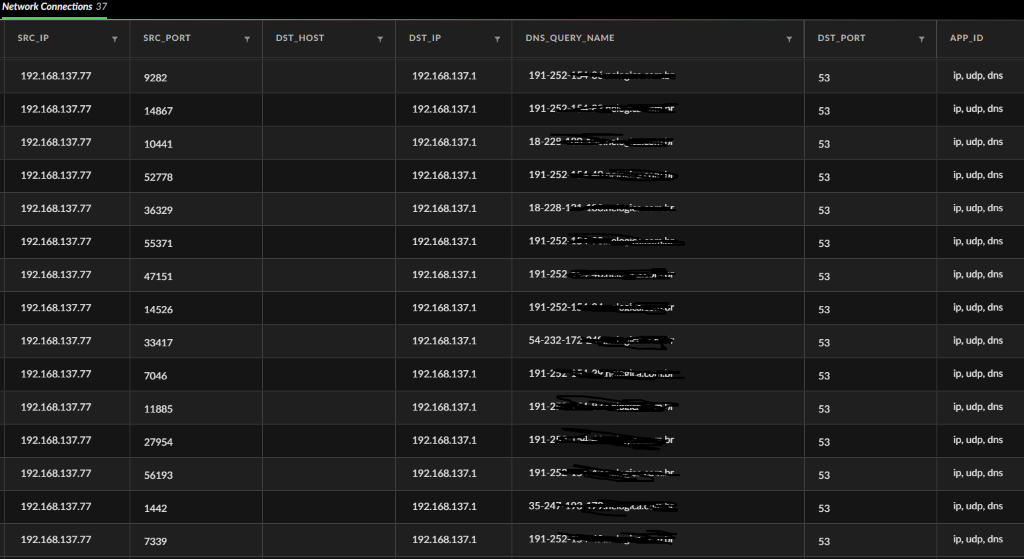
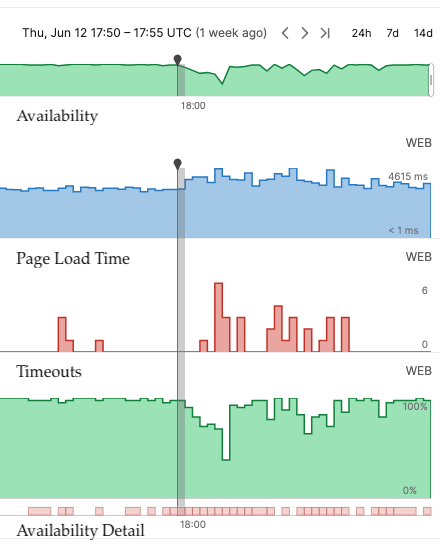
Neste período do ano, empresas costumam atuar com equipes reduzidas, fato que resulta em um número notavelmente menor de colaboradores ativos e capazes de identificar mudanças ou mau funcionamento dos sistemas utilizados internamente. Os atacantes sabem disso e abusam dessa situação. Afinal, quanto menos olhos voltados para ações disruptivas no sistema, maior a chance de um ataque cibernético passar despercebido.
A diminuição do contingente pode afetar diretamente o tempo de resposta dos potenciais incidentes, fazendo com que alertas se acumulem, investigações sejam postergadas e ações de contenção ocorram de maneira tardia.
Atente-se às promoções relâmpago de fim de ano!
Todo mundo já recebeu aquele e-mail de origem duvidosa informando que está ocorrendo uma promoção “imperdível” do panetone que antes custava R$ 300,00 e que, para você, sortudo(a), está agora custando “APENAS” R$ 29,99. Lembre-se: o barato pode sair caro. O número de casos de golpes, fraudes e phishing aumenta gradativamente em períodos festivos, portanto, fique alerta, desconfie!
Se não for crítico ou essencial; Desative! Desligue! Esconda!
Muitas atividades são pausadas no ambiente corporativo durante o fim do ano, por inúmeros motivos, desde a reformulação de processos internos até transições de ferramentas. Com base nisso, muitos serviços ativos, como páginas publicadas na internet e servidores com portas RDP expostas para o mundo, acabam sendo esquecidos e permanecem em operação sem o devido gerenciamento e cuidado. Lembre-se: serviços ativos esquecidos podem servir como um convite para a ceia de Natal destinada a atores maliciosos.
Aproveite o período de festas de fim de ano com menos preocupações
Seguindo alguns passos simples, é possível reduzir muito sua superfície de ataque. Isso não significa que você não sofrerá um ataque cibernético neste fim de ano, porém, ao seguir essas dicas, garanto que os riscos serão bem menores, e as chances de aproveitar as festas de fim de ano sem maiores problemas são mais favoráveis.
- Desative contas de serviço que não serão utilizadas nesse período festivo
- Faça uma revisão na sua rede em busca de serviços não essenciais ativos e expostos para a internet
- Desconfie de promoções milagrosas, consulte a informação nos sites oficiais
- Não deixe correções de vulnerabilidades para o ano que vem, pode ser tarde demais!
- Não ignore os alertas de segurança, eles não são enfeites de árvore de Natal
- Revise políticas de senhas de usuários e ativação de MFA
Fontes
https://securityleaders.com.br/golpes-ciberneticos-disparam-no-fim-de-ano-afirma-analise
Graduado em Análise e Desenvolvimento de Sistemas pela Universidade Paulista, e Pós-graduando em “Defensive Cyber Security” pela FIAP, atua como N1 no time de SOC da CYLO, é responsável por realizar a primeira análise e resposta de incidentes cibernéticos, realizou capacitações no campo de SOC/CSIRT, tendo como destaque os treinamentos promovidos pela CERT.BR em conjunto com a instituição Carnegie Mellon University “Foundations of Incident Management” e “Advanced Topics in Incident Handling”